序言
这篇教程也算是我的一个学习总结吧,当然我也不是多牛B,花了一年时间才刚刚入门C++,学C++也就是用来娱乐一下,也没弄出来什么高端的东西,所以当然不要期盼从这学到多前沿的工程技巧,毕竟这只是一篇导论嘛,我也只是整理了一些我读过的书上提到的知识,没什么创新点。真正的大佬估计看几秒就索然无味了(逃
这篇教程可能更适合有一些 C++ C with class语言基础,但是对于OOP思想还不甚了解的同学。
其实三个月之前就写过一个类似的教程知识点总结,还拿给和我一起写大作业的同学看。那篇知识点总结和这篇博客的想介绍的东西差不多,不过因为之前我还没有给自己写的东西有一个明确的定位而且写的比较仓促,所以写的乱七八糟。不过之前那片的稿子我已经丢了,正好可以重新开始写一篇,而且现在期末复习阶段课内作业都变少了,我也有足够的时间来写这个。
毕竟我也只是入门级水平,估计叙述中会有不严谨的地方,欢迎大家反馈给我。
面向对象
按照primer上的说法,OOP的核心是数据抽象、继承和动态绑定。
- 数据抽象的核心是将接口和实现分离,分离之后接口的部分就是抽象出来的数据类型,从设计者的角度看,一个数据类型只取决于这个类型上支持的操作,因此一些动态语言会有“鸭子类型”的概念,C++中是没有“鸭子类型”的说法的。在C语言中,接口可以理解为函数声明,实现可以理解为函数定义。在C++中,一般情况下定义了一个类就被认为是定义了一个类型,接口可以理解为这个类定义的那些public成员函数(用户视角),因为一般情形下用户只关心这个类型上支持什么操作,而不关心这些操作如何实现;也可以理解为这个类的定义(不包括成员函数定义,包括成员函数声明),就是代码里
class Shit{...};这段内容(编译器视角)。而实现都指的是这个类的成员函数定义。这里提到的“用户”是指使用你编写的类的程序员,希望我们在这一点上没有歧义。
我将编译器如何看待接口与实现分离区分出来,是考虑到了不同.h或是.cpp文件之间是有编译依存性的。如果单纯的做OOA&D,只需考虑如何在各个类之间解耦就好了,但是苦逼的C++程序员还要考虑如何在不同编译单元之间解耦;理想情况是我改动了一个编译单元,只要重新编译这一个文件然后再和其他编译单元链接就好了,比较坏的情况是我改动了一个编译单元,What the …怎么整个工程全都要重新编译了,最理想的情况是超大工程改一行代码可以直接编译到下班。你看Java程序员就不用担心这些(逃。为了解决这个问题,C++中有一个经典的技巧叫 pImpl(pointer to implementation)(挖坑不填,(tao
继承。为了实现多态,继承还是很有必要的。如果从语法上细分的话,有public,private,protected三种继承方式,再结合每个类中成员也有这三种访问控制级别,组合一下就有一大堆乱七八糟要记忆的可访问性。而且要体现protected继承的效果必须要多于一层的继承体系,这就更麻烦了,不过我在学C++的过程中几乎没有哦看到过哪些代码用了protected继承(只为了说明protected继承效果的语法教程不算),所以也不会在这篇文章中介绍protected继承。不过我还是要假设读者对其他继承方式在语法上有足够了解。
动态绑定。这不就是多态嘛。我可以只用基类提供的那套接口,但是获得不同的实现,即一套接口可以绑定到不同的实现上,这些不同实现在派生类里完成。这就涉及到虚函数了,要探究语言层面的底层实现的话还会涉及到vtbl和vptr,本文中会提一下,但不会涉及太深,想深入研究的同学移步《深度探索C++对象模型》,据说很经典的一本书,但我没看过,就不便多做评论了。
两个设计上的好习惯
(1)private 数据成员变量
当然要将数据成员变量声明为private了!这也不是个人偏好,这是前人无数次采坑之后总结出来的法则,也只有这样才能体现出封装的好处。
首先,很多数据成员其实根本没有必要让外部访问的,它们可能只是维护一下该对象的内部状态,比如说一个表示文本文件的类TextFile,维护一个bool型成员变量表示文本文件是否被修改过:1
2
3
4
5
6
7
8
9class TextFile
{
public:
bool close(); //try to close the file
...
private:
bool isModified; //check if the file needs saving when closing it
...
};
如果改文本文件被修改过,就将改标志置为true,然后关闭文件时会检查该标志,如果该标志被置位则询问是否保存该文件。那这个标志有没有被置位让这个类的对象自己管理就好了嘛,用户不需要操心这个,因此将其声明为private是完全合理的。
而且,就算真的需要外部访问,一般也不允许直接访问的,而是要写成这样:1
2
3
4
5
6
7
8
9
10class Data
{
public:
const int getData(); //optional
void setData(int data); //optional
...
private:
int m_data;
...
};
通过选择性地给出get和set函数,就可以控制m_data的访问方式(只读、只写、可读可写),而如果直接将m_data声明为public就没有这种效果。
将成员变量设为public有一个最大坏处。假设刚开始做设计的时候把某个成员变量设为public,但是后来需求变更了,比如说要在写这个成员变量的时候发送一个信号通知这个对象的一些observer该变动事件发生,或者只是希望在改变该成员变量的时候打个log记录一下,等等。这时候该类的程序员把这个变量重设为了private,并提供访问函数来读或写这个变量,在该函数中实现notify或然后编译,链接,然后发现所有直接访问这个成员变量的用户代码全都GG了,所有这些用户代码全都要重写一遍。与其这么折腾,还不如在开始设计的时候就只提供成员函数来访问该成员变量,这样就保留了日后变更实现的权利。
你可能会问protected访问说明符对访问权限的控制能力,答案是:它不比public有更好的封装能力。总有奇淫巧计可以获取一个protected成员的引用,比如用户可以定义一个类继承自原来的类,然后在这个派生类中提供一个public成员函数返回基类那个protected成员的引用,因此用户代码还是可以访问到protected成员变量。当然这种访问方法是很垃圾的设计,我们自己写代码不要这么写。但是,不要假定使用你写的类的用户不会这么干,有一句忠告说的好:
只要一件事没有被明令禁止,一定会有人做这件事
因此最好的做法就是,从语法层面禁止用户访问数据成员变量。
当然你可能还有一个疑问,假如我能确定一定不会有后期的需求变更,这个类的唯一作用就是将一组数据打包到一起呢?那当然可以直接将数据成员暴露给用户了!经典的例子是一个IPv4头:1
2
3
4
5
6
7
8
9struct IPv4Header{
std::unit32_t
version:4,
IHL:4,
DSCP:6,
ECN:2,
totalLength:16;
...
};
这里用到了位域,可以提供存储压缩,想了解的同学可以了解一下,不想了解也不会影响你学习这篇教程里的东西,跳过就好了。
一个建议是仅当只有数据成员时用struct,其他情形用class,来自Google开源项目风格指南。
但是,在大多数情形下,我们还是要将数据成员变量声明为private。
(2)虚析构函数
如果一个类是用作多态用途的(一般这种类会内含至少一个除了析构函数之外的虚函数),那一定要为让类有一个虚析构函数。这个很重要。因为不这样做往往会引发undefined behavior(结果往往是对象的derived部分没有被销毁):
If the static type of the object that is being deleted differs from its dynamic type (such as when deleting a polymorphic object through a pointer to base), and if the destructor in the static type is virtual, the single object form of delete begins lookup of the deallocation function’s name starting from the point of definition of the final overrider of its virtual destructor. Regardless of which deallocation function would be executed at run time, the statically visible version of operator delete must be accessible in order to compile. In other cases, when deleting an array through a pointer to base, or when deleting through pointer to base with non-virtual destructor, the behavior is undefined.
摘自cppreference。
Talk is cheap, show you the code:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class Widget
{
public:
widget();
virtual ~widget();
//~widget(); don't do this
...
private:
int a;
};
class SpecialWidget: public Widget
{
...
private:
int b;
};
int main()
{
Widget *pW = new SpecialWidget;
...
delete pW; //if ~widget() is not virtual, this lead to undefined behavior
return 0;
}
如果想再深究一下原因,为什么会引发UB,那是因为编译器会误认为它要delete的对象大小和基类大小一样,而其实派生类对象的大小往往比基类大一些(如果派生类没有自己的数据成员大小一般和基类是一样的),显然编译器不喜欢被欺骗,他会在调用operator delete的时候传递(往往)不正确的size_t类型参数,从而引发UB。
上面引用cppreference的部分提到了通过基类指针删除派生类数组会导致UB,我再补充说明一下这个问题,虽然我觉得很少有人会这么干:1
2
3Widget *pW = new SpecialWidget [10];
...
delete pW; //undefined behavior
这个就和基类有没有虚析构函数无关了,只要敢这么写,一定是UB,还是因为operator delete []的size_t参数传递的问题。这么做的同学的动机可能是觉得只要是基类指针,就能通过让它指向派生类的对象来体现多态,其实真要想这么干,应该用指针数组而不是普通数组嘛。《More Effective C++》条款3对这个问题有更深入一点的讨论,想了解更多的同学可以看这本书。
但要注意一下一般只有用于多态的基类才有虚析构函数的需求,不是所有的类都用做多态用途的。如果没有必要使用虚析构函数就不要这么做了,这样反而会造成额外开销(会引入vtbl和vptr这些东西,浪费了几个指针的空间,本文后面会提到这些)。
另外一种建议声明虚析构函数的地方是:有时候你希望拥有抽象类,但手头又没有纯虚函数,这时候可以选择将析构函数声明为纯虚函数,这种情况下必须为纯虚析构函数提供定义,因为编译器此时不会自动生成析构函数的定义(我认为是因为编译器自动生成的析构函数都是inline的,而纯虚函数又不能定义在类的内部,即必须不是inline的,所以无法自动生成纯虚析构函数的定义)。
你可能又有疑问:抽象类不一般都用作接口嘛,接口类一般都用作多态的吧,那怎么会没有其他的虚函数呢?嗯,是这样的(前半句),但总有例外,比如混入类(Mixin Class)了解一下?
按我的理解来解释一下这个技术:就像以前写C语言代码时有两个函数用用到了相同的代码段,为了贯彻DRY原则,好的设计者会把这两个函数中重复的部分抽出来形成一个新函数,让之前的两个函数在内部去调用这个新函数。在C++里类似地,如果有两个类都需要实现一部分相同的功能,一个可选的设计是将重复的部分抽出来形成一个新类,然后让原来的两个类都继承自这个类,然而这个类仅仅是为了减少重复代码而出现的,并不需要实例化出对象,所以干脆直接设为抽象类(还记得吗,上面刚说过,如果不想给用户做一件事的权利,就从语法层面禁止这件事的出现)。
关于这个技术的细节不想在这个入门教程里提了,有兴趣的同学可以看《More Effective C++》条款27,有一个使用这个技术的例子。
接口与实现,继承与复合
《Effective C++》和《设计模式》中对一些相同概念有不同的叫法,这些概念有些比较重要,因此在这里简单区分一下,后面会详细说明其中几个点。
Scott Meyers(《Effective C++》作者)区分了类与类之间三种不同关系:
- public 继承表示 is-a 关系
- 复合(composition)表示 has-a 或 is-inplemented-in-terms-of 关系
- private 继承表示 is-inplemented-in-terms-of 关系
这里插一句:(Scott Meyers:)复合(composition)是类型间的一种关系,当某种类型的对象内含其他类型的对象,便是这种关系。后面“区分 复合 与 private继承”一节会仔细说明。
然后将 public 继承又分为两类:
- 接口继承
- 实现继承
GoF(《设计模式》作者)先是区分了:
- 类继承 (对应 Scott Meyers 说的 private 继承)
- 接口继承 (对应 Scott Meyers 说的 public 继承,注意这里的接口继承和Scott Meyers说的接口继承不一样)
并提出了一个设计准则:
针对接口编程,而不是对实现编程
然后又区分了(表现出 Scott Meyers 说的 is-inplemented-in-terms-of 关系的两种方式):
- 类继承 (对应 Scott Meyers 说的 private 继承)
- 对象组合 (对应 Scott Meyers 说的“复合”中表现 is-inplemented-in-terms-of 关系的那部分)
并提出第二个设计准则(考虑到继承常被认为破坏了封装性,注意这里的目标是功能复用,而不是多态,要表现多态使用继承是理所当然的):
优先使用对象组合(复合),而不是类继承(private 继承)
然后针对对象组合又区分了
- 聚合(aggregation)(被写死的编译时刻结构)
- 相识(acquaintance)(可变的运行时刻结构)
区分 接口继承 与 实现继承
这一小节使用Scott Meyers的思路,首先要知道 public 继承表示 is-a 关系:
如果你令
class D(“Derived”)以 public 形式继承class B(“Base”),你便是告诉C++编译器(以及你的代码读者)说,每一个类型为 D 的对象同时也是一个类型为 B 的对象,反之不成立。你的意思是 B 比 D 表现出更一般化的概念,而 D 比 B 表现出更特殊化的概念。你主张“ B 对象可派上用场的任何地方,D 对象一样可以派上用场”(译注:此即所谓Liskov Substitution Principle),因为每一个 D 对象都是一种(是一个)B 对象。反之如果你需要一个 D 对象,B 对象无法效劳,因为虽然每个 D 对象都是一个 B 对象,反之并不成立。
里面提到了里氏替换法则(Liskov Substitution Principle)
这里的 is-a 关系表现的就是多态,也即想表现多态必须使用 public 继承,从语法角度分析也会得到这个结论,另外两种继承方式都会(从C++语法上)禁止从派生类(通过指针或引用)到基类的转型。
大体上,public 继承表示 is-a 关系没有问题,但是总有例外,比如上面提到的 Mixin Class 可以是公有继承,但是这可不是 is-a 关系,是基类完成了子类的一个功能子集,反倒有点像 is-inplemented-in-terms-of 关系了。
了解了 public 继承的含义,就可以细分在 public 继承中进一步区分的接口继承(不是GoF说的接口继承)与实现继承了。
(1)成员函数的接口总是会被继承
C++继承体系中,成员函数大致可以分为一下三种:
- 非虚函数
- 虚函数
- 纯虚函数
- 非纯虚函数
不论是哪种成员函数,接口总会被继承。假如基类中声明了一个public成员函数fxck(),那所有的派生类对象都可以把它当作自己的成员函数来调用的,不管这个成员函数virtual不virtual,pure不pure。
(2)声明一个纯虚函数的目的是让派生类只继承函数的接口
在C++中带纯虚函数的类都是抽象类,而抽象类一般都做接口类使用,正是依赖了这个道理(小标题)。该抽象类告诉继承自它的具体类:你必须为所有的纯虚函数提供一份定义,但我不干涉你怎样实现它。C++语法规定:假如派生类不为纯虚函数提供定义,那这个派生类依旧会是一个抽象类。举个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class EditCommand //abstract class as interface
{
public:
virtual void do() = 0;
virtual void undo() = 0;
virtual void error(const std::string &msg); //must be defined somewhere
std::uint64_t executeTime();
};
class InsertCommand : public EditCommand
{
public:
//these functions shall be implemented somewhere
virtual void do() override;
virtual void undo() override;
};
class EraseCommand : public EditCommand
{
public:
//these functions shall be implemented somewhere
virtual void do() override;
virtual void undo() override;
};
InsertCommand和EraseCommand继承了抽象类EditCommand的接口,但是为里面的函数提供不同的定义,InsertCommand里的do()是插入操作,undo()是删除操作,而EditCommand里的do()是删除操作undo()是插入操作。
实际上也可以(选择性地)为纯虚函数提供一份定义(而非纯虚函数则必须定义),调用它的唯一途径是通过域运算符,像EditCommand::do();这样。使用这种方法的时机可以是:有时候如果一些派生类的do()函数中要执行一部分相同操作(比如说发个信号或打个log什么的)时,把公共的部分放到抽象类do()的定义中,然后在其派生类的do()函数实现中先通过域运算符调用基类do()函数,再写自己特殊的部分,这样可以减少代码重复,以后有需求变更要改代码时会从中受益。
(3)声明一个非纯虚函数的目的是让派生类继承函数的接口和缺省实现
非纯虚函数是必须定义的,这份定义也就成了缺省实现。同时其派生类也可以选择不再定义这个函数(纯虚函数就没有这种选择权),那就相当于采用了缺省实现,
比如上面例子中EditCommand有一个error(const std::string &msg)函数,意味着提供了一份缺省错误处理行为,它的子类们可以使用这个缺省实现,也可以自己重新定义一个自己专属的实现方式。
(4)声明一个非虚函数的目的是让派生类继承函数的接口和缺省实现
比如上面实例中EditCommand的std::uint64_t executeTime()函数,希望对所有命令的开始执行的时间点有一个统一的表示方法,因此讲该函数声明为非虚函数,提供了一份强制性实现来确保该表示的一致性。
一个设计上的好习惯是绝不重新定义继承来的非虚函数,因为这样做容易产生(设计上的)歧义,会给使用该继承体系的用户造成困扰。
区分 复合 与 private继承
语法上,复合与private继承完全不是同一个东西,不过它们在面向对象设计中可以表现相同的功能(is-inplemented-in-terms-of 关系),当然也有很多不同,因此在这里区分一下。
复合
前面已经提到:
复合(composition)是类型间的一种关系,当某种类型的对象内含其他类型的对象,便是这种关系。
2
3
4
5
6
7
8
9
10
11
class PhoneNumber { ... };
class Person {
public:
...
private:
string name; // 下层对象
Address address; // 同上
PhoneNumber voiceNumber; // 同上
PhoneNumber faxNumber; // 同上
};
本例中,Person 类被认为是置于 string,Address 和 PhoneNumber 类的 上层,因为它包含那些类型的数据成员。”分层” 这一术语有很多同义词,它也 常被称为:构成(composition),包含(containment)或嵌入(embedding)。
区分 has-a 关系和 is-inplemented-in-terms-of 关系
按照Scott Meyers的观点,复合可以表现两种关系:
- has-a
- is-inplemented-in-terms-of
需要与private继承区分的是后者。在这里为了完整性,两个都会说明一下,还是引用Scott Meyers的话吧,我讲的不会比他好:
复合意味着 has-a(有一个)或 is-inplemented-in-terms-of(根据某物实现出)。那是因为你正打算在你的软件中处理两个不同的领域(domains)。程序中的对象其实相当于你所塑造的世界中的某些事物,例如人、汽车、一张张视频画面等等。这样的对象属于应用域(application domain)部分。其他对象则纯粹是实现细节上的人工制品,像是缓冲区(buffers)、互斥器(mutexes),查找树(search trees)等等。这些对象相当于你的软件的实现域(implementation domain)。当复合发生于应用域内的对象之间,表现出 has-a 的关系;当他发生于实现域内则是表现 is-inplemented-in-terms-of 的关系。
上述的 Person class 示范 has-a 关系。Person 有一个名称,一个地址,以及语音和传真两个电话号码。
至于使用复合表示 is-inplemented-in-terms-of 关系的例子,比如说标准库里的 stack:1
2
3
4template<
class T,
class Container = std::deque<T>
> class stack;
默认是使用 deque 来实现栈的功能的,并且采用的是复合的方式实现复用,而不是 private 继承(题外话:这里也可以看作一个适配器(Adapter)模式的例子)。
区分 聚合(aggregation)与 相识(acquaintance)
引用《设计模式》中的话:
考虑对象聚合和相识的差别以及它们在编译和运行时刻的表示是多么的不同。聚合意味着一个对象拥有另一个对象或对另一个对象负责。一般我们称一个对象包含另一个对象或者是另一个对象的一部分。聚合意味着聚合对象和其所有者具有相同的生命周期。
相识意味着一个对象仅仅知道另一个对象。有时相识也被称为“关联”或“引用”关系。相识的对象可能请求彼此的操作,但是它们不为对方负责。相识是一种比聚合要弱的关系,它只标识了对象间较松散的耦合关系。
聚合和相识很容易混淆,因为它们通常以相同的方法实现。Smalltalk中,所有变量都是其他对象的引用,程序设计语言中两者并无区别。C++中,聚合可以通过定义表示真正实例的成员变量来实现,但更通常的是将这些成员变量定义为实例指针或引用;相识也是以指针或引用来实现。
上面的那段话里 Smalltalk 换成 JAVA 也是成立的,Smalltalk 现在几乎没人用了。如果想要可变化的运行时结构的话,相识关系还是最好用(智能)指针而不是引用来表示(虽然引用一般在编译器中也是以指针来实现)。
区分这些有什么用,emmm,其实主要的区别是它们一个表示强耦合,另一个表示弱耦合。按我的理解,在做面向对象设计的时候,一般有强耦合关系的类,在设计其中一个的时候总要考虑对另一个的影响(这样的类一般放一起一起设计),一个类如果后期发生了变化,另一个类也往往要跟着变化,就比较烦,但是如果两个类本来就有这种强耦合关系的话设计成这样也是当然可以的,比如这节最开始的 Person class 的例子。弱耦合意味着一个类的变化对另一个类的影响较小,这是大部分面向对象程序员在做设计的时候追求的东西:解耦(decoupling)。这样的设计对后期变化的适应性更强一些,在改动一个类的代码时,一般可以(几乎)不改动另一个类的代码,因为一般情况下类的已有接口都是很少改动的。
在 UML(标准建模语言)中,GoF说的聚合关系被进一步细分为聚合关系(UML中的聚合,是GoF说的聚合的一个子集)和组合关系,GoF说的相识关系,对应 UML 中的关联关系。并且 UML 中又引入了一种 依赖关系,这是一种更弱的耦合关系。
参考了这篇博客
private 继承
首先C++语法就规定了,如果两个类之间采取 private 继承,那么从派生类(通过指针或引用)到基类的转型是不被允许的,至少在用户代码里是这样(在派生类内部可以使用该转型),这意味着你无法使用 private 继承表现多态,。并且采用 private 继承的基类中所有 public 和 protected 成员的访问级别均会变为 private。这些事实说明:
private 意味着只有实现部分被继承,接口部分应略去。如果 D 以 private 形式继承 B,意思是 D 对象根据 B 对象实现而得,再没有其他意涵了。
在 复合 与 private继承 间取舍
《设计模式》中通在可见性的角度对两者进行了客观的分析(下面的类继承可以全都理解成 private 继承):
面向对象系统中功能复用的两种最常用技术是类继承和对象组合(object composition)。正 如我们已解释过的,类继承允许你根据其他类的实现来定义一个类的实现。这种通过生成子类的复用通常被称为白箱复用(white-box reuse)。术语“白箱”是相对可视性而言:在继承方式中,父类的内部细节对子类可见。
对象组合是类继承之外的另一种复用选择。新的更复杂的功能可以通过组装或组合对象来获得。对象组合要求被组合的对象具有良好定义的接口。这种复用风格被称为黑箱复用(black-box reuse),因为对象的内部细节是不可见的。对象只以“黑箱”的形式出现。
并且给出了一个设计(取舍)原则:
优先使用对象组合,而不是类继承
Scott Meyers也在《Effective C++》中有类似的表述:
尽可能使用复合,必要时才使用 private 继承
原因主要有2个:
- 继承对子类揭示了其父类的实现细节,比如子类可以重新定义父类的 virtual 函数,所以继承常被认为“破坏了封装性”。
- private 继承不利于降低编译依存性。当派生类被定义时,子类的定义必须可见,而降低编译依存性的一个常用操作是只提供类的声明式而非定义式,private 继承就没有给我们这种权利。
另一个问题出现了,既然上面只是建议优先使用复合,那什么时候是使用 private 继承的合理时机呢?
Scott Meyers提到了两种情况:
- 当派生类希望访问基类的 protected 成员或重新定义基类的 virtual 函数的时候
- 对于空间有极端要求的时候,EBO(empty base optimization;空白基类最优化)了解一下(我觉得这个需求很少见,就不展开说明了,有兴趣的同学移步《Effective C++》条款39)
但是《设计模式》中又给出了忠告(下面的继承理解成 private 继承):
然而,我们的经验表明:设计者往往过度使用了继承这种复用技术。但依赖于对象组合 技术的设计却有更好的复用性(或更简单)。你将会看到设计模式中一再使用对象组合技术。
vtbl,vptr,RTTI
最后我们来简单介绍一下vtbl和vtpr,了解了这些,就可以对虚函数、RTTI的成本有直观一点的认识了。
这一节大量引用《More Effective C++》条款24中的内容,就不在文中用引用区块标识了。
我们都知道当虚函数被调用的时候,调用的是基类函数还是派生类函数是由对象的动态类型决定的。那么编译器就必须提供一套实现这个功能的机制,大部分编译器都使用vtbl(virtual table)和vptr(virtual table pointer)这套机制。
vtbl 通常是一个由函数指针组成的数组,所有声明或继承了虚函数的类,都会有自己的 vtbl,其中放着该类中各个虚函数实现体的指针。
《More Effective C++》中的例子:1
2
3
4
5
6
7
8
9
10class C1 {
public:
C1();
virtual ~C1();
virtual void f1();
virtual int f2(char c) const;
virtual void f3(const string& s);
void f4() const;
...
};
C1 的 virtual table 数组看起来如下图所示:
如果另一个 C2 类继承自 C1,像这样:1
2
3
4
5
6
7
8class C2: public C1 {
public:
C2(); // 非虚函数
virtual ~C2(); // 重定义函数
virtual void f1(); // 重定义函数
virtual void f5(char *str); // 新的虚函数
...
};
则 C2 的 vtbl 如下图(这些项目包括指向没有被 C2 重定义的 C1 虚函数的指针):
只有 vtbl 是不行的,因为每个有 vtbl 的类的对象需要能够找到 vtbl 的位置,vptr( virtual table 这样一个辅助完成这项工作的指针,它指向 vtbl 的地址。vptr 是一个看不见的数据成员,它在对象中的位置只有编译器才知道。
一个包含多个 C1 和 C2 对象的程序,大概长这样: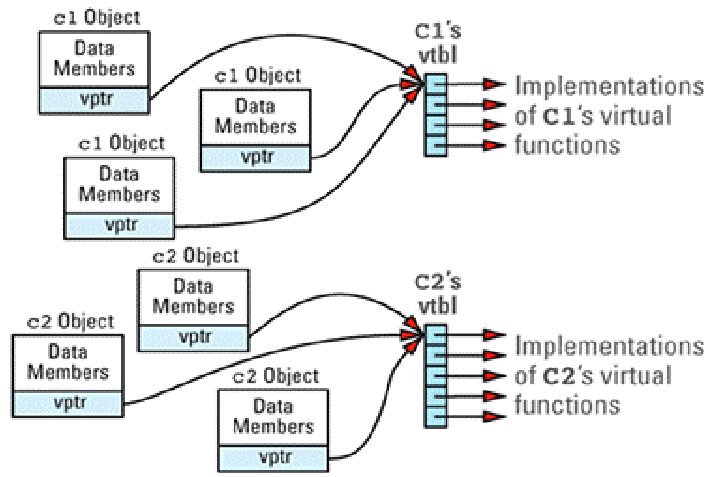
因此对于一个虚函数调用:1
2C1 *pC1;
pC1->f1();
编译器生成的代码会做这些事:
- 通过对象的 vptr 找到类的 vtbl。这是一个简单的操作,因为编译器知道在对象内哪里能找到 vptr(毕竟是由编译器放置的它们)。因此这个代价只是一个偏移调整(以得到vptr)和一个指针的间接寻址(以得到 vtbl)。
- 找到对应 vtbl 内的指向被调用函数的指针(在上例中是 f1)。这也是很简单的,因为编译器为每个虚函数在 vtbl 内分配了一个唯一的索引。这步的代价只是在 vtbl 数组内的一个偏移。
- 调用第二步找到的的指针所指向的函数。
如果我们假设每个对象有一个隐藏的数据叫做 vptr,而且 f1 在 vtbl 中的索引为 i,
此语句pC1->f1();
生成的代码就是这样的1
2
3
4(*pC1->vptr[i])(pC1); //调用被 vtbl 中第 i 个单元指
// 向的函数,而 pC1->vptr
//指向的是 vtbl;pC1 被做为
// this 指针传递给函数。
现在可以总结一下使用虚函数的成本了:
- 空间成本:需要额外的内存空间来存放 vtbl 和 vptr。在内存不太够的系统中可能要考虑一下这个空间成本,而且这个空间成本还可能间接带来一些时间成本,因为对象较大意味着较难塞入一个缓存分页(cache page)或虚内存分页(virtual memory page)中,也就意味着换页活动可能增加。
- 时间成本:因为是通过函数指针间接调用的函数,会有额外的寻址时间,不过这几乎与调用非虚函数效率一样。在大多数计算机上它多执行了很少的一些指令,虚函数本身通常不是性能的瓶颈。
- 相当于放弃了 inline。当通过对象调用虚函数时,它其实是可以被内联的,但是大多数虚函数是通过对象的指针或引用被调用的,这种调用不能被内联(一个 inline 函数若要被取地址,编译器通常必须为该函数生成一个 outlined 本体)。因为这种调用是标准的调用方式,所以虚函数实际上相当于不能被内联。
既然这里把 vtbl,vptr 和 RTTI 放到同一节,你可能也已经想到了 RTTI 也是借助了 vtbl 来实现的。事实上C++语法规定只有当某种类型至少有一个虚函数,才能保证运行时类型识别正常工作,参考Polymorphic objects。
例如,vtbl 数组的索引 0 处可以包含一个 type_info 对象的指针,这个对象属于该 vtbl
相对应的类。上述 C1 类的 vtbl 看上去象这样:
最初我读到这里的时候想,那 dynamic_cast 的成本岂不是就和调用虚函数差不多了,为什么各种书上还说 dynamic_cast 成本高而不推荐使用呢?后来翻书(《Effective C++》)又看到了 dynamic_cast 一个很普遍的实现版本基于“class名称的字符串比较”,继承体系越深,dynamic_cast 的成本就越高。所以依旧不推荐使用 dynamic_cast(尽量还是用虚函数替代)。
最后有一个 vtbl,vptr 和 RTTI 代价总结
| Feature | Increases Size of Objects | Increases Per-Class Data | Reduces Inlining |
|---|---|---|---|
| Virtual Functions | Yes | Yes | Yes |
| Virtual Base Classes | Often | Sometimes | No |
| RTTI | No | Yes | No |
《More Effective C++》条款24中还有关于当多重继承混入时的讨论,这里没有提到,有兴趣的同学自己看书吧(逃